This is the problem that I have been facing recently. A client asked me to process data from hundreds of Excel files. Frankly, I didn’t want to spend hours extracting this data manually. So, I automated the process with Anatella and visualized the data using Tableau afterward. Here’s a little tutorial on data preparation and an excellent way to process your data more efficiently with an ETL worthy of the name.
If you only have 30 seconds
- using Anatella, I was able to automate the process of extracting data from Excel files.
- it allowed me to accelerate and sustain a process that was previously tedious and prone to errors due to manual processing
- the method used is based on a loop launching treatments on Excel files located in a defined folder
- a consolidated file is produced in output that I can use in Tableau
A description of the problem
The problem that I was faced with is relatively common. As part of a project assigned to me by Parliament, I was asked to produce statistics on the employment of persons with disabilities in public administration.
Once a year, each municipality is required to fill in a template Excel file, documenting a whole series of indicators: number of FTEs, gender, reference salaries, number of jobs entrusted to people with disabilities, and so on. The good news is that the administrations in question respect the template and write the information in the right place. The problem is that the templates are not always complete, some are missing, and there are many files. It is, therefore, necessary to go over it several times before having consolidated data.
The first solution would have been to process each file individually after correcting the errors in it. This is time-consuming and not sustainable. I would have had to start over again every year. Above all, it would have involved multiple trips back and forth with the central administration to retrieve the files one by one as they were sent. This would have slowed me down considerably.
The right approach is to create a data extraction and structuring “pipeline.” This pipeline runs automatically and allows me to update my data set on the one hand effortlessly and my visualizations using Tableau on the other. Here is how I approached the problem with Anatella.
Solution
The developed solution is divided into two main steps:
- a pipeline to extract the data from each file and restructure them
- a pipeline to process at the same time all the files in a given folder
Step 1: extraction of data from the Excel file and re-formatting
The first step is, therefore, to extract the information from specific cells in the Excel files. To do this, I use a ternary operator. The (very handy) “unflatten” feature then allows me to structure all the data on a single line, laying the foundation for the file format needed for Tableau. Finally, I write a .gel file in the same folder as the Excel file.

Step 2: file processing loop
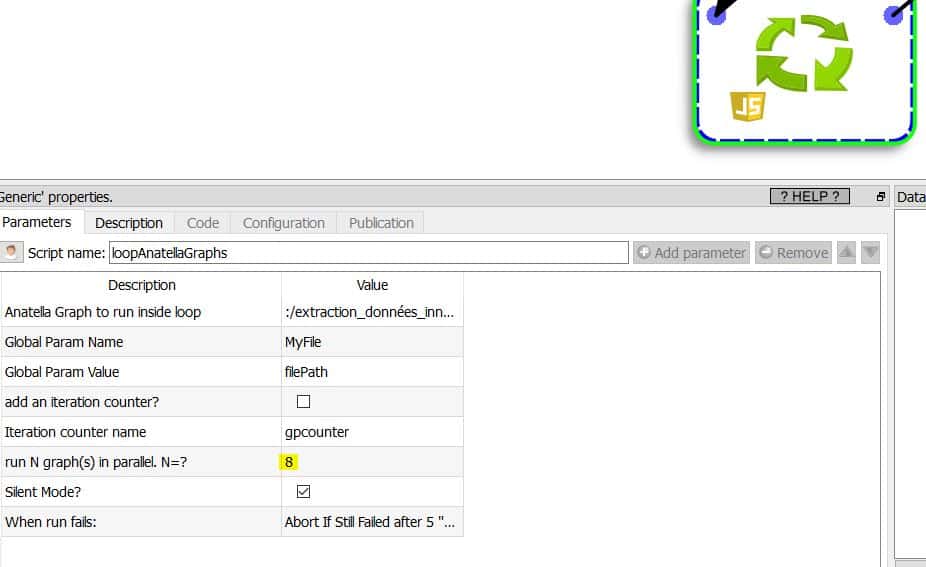
The 2nd step consists of creating a loop that will call each processing sequence of the Excel files and write a series of .gel files.
Tip: you can run several processes in parallel if your CPU has several cores. I use an i7 CPU with 8 cores, which allows me to run 8 operations in parallel. The processing time for the whole process is 4.31 seconds instead of about 32 seconds. The gain is appreciable. As an output, I only need an Excel file (I could also have chosen a .hyper file).


Conclusion
Thanks to Anatella, I could automate a data extraction process that otherwise would have taken me hours. Another significant advantage is that this automated process is future-proof and will allow me to ingest the new files and automatically update my visualizations if the Excel templates do not change in the future.
Posted in big data.