In veel voorkomende situaties kan fuzzy matching een erg handige techniek zijn. Ik vergeleek een fuzzy matching-feature van Alteryx met die van Anatella. Ik besprak fuzzy matching overigens al eens eerder, namelijk in dit artikel. Omdat de functionaliteit van fuzzy matching in Tableau Prep builder niet helemaal opleverde wat ik verhoopte, wilde ik nagaan wat Alteryx in zijn mars had. Uiteindelijk geeft Anatella de betere resultaten en verloopt de programmering van het ETL-proces er veel efficiënter.
Samenvatting
- Inleiding over fuzzy matching met Alteryx
- De 3 stappen van fuzzy matching met Alteryx
- Resultaten: Alteryx vs. Anatella
- Conclusie

Inleiding om vertrouwd te raken met fuzzy matching
Om zicht te krijgen op de basis van fuzzy matching in Alteryx bekeek ik deze video (Engels). Doe dat zeker als u er ook aan wilt beginnen.
Het principe dat wordt toegelicht is gebaseerd op fuzzy matching in een enkele tabel. Het proces in Alteryx vereist dat er een koppeling wordt gemaakt tussen 2 tabellen van hetzelfde formaat alvorens het proces van fuzzy matching kan worden uitgevoerd. Ik ben me er volledig van bewust dat dit een belangrijke beperking is, maar ik kom iets later in het artikel hierop terug.
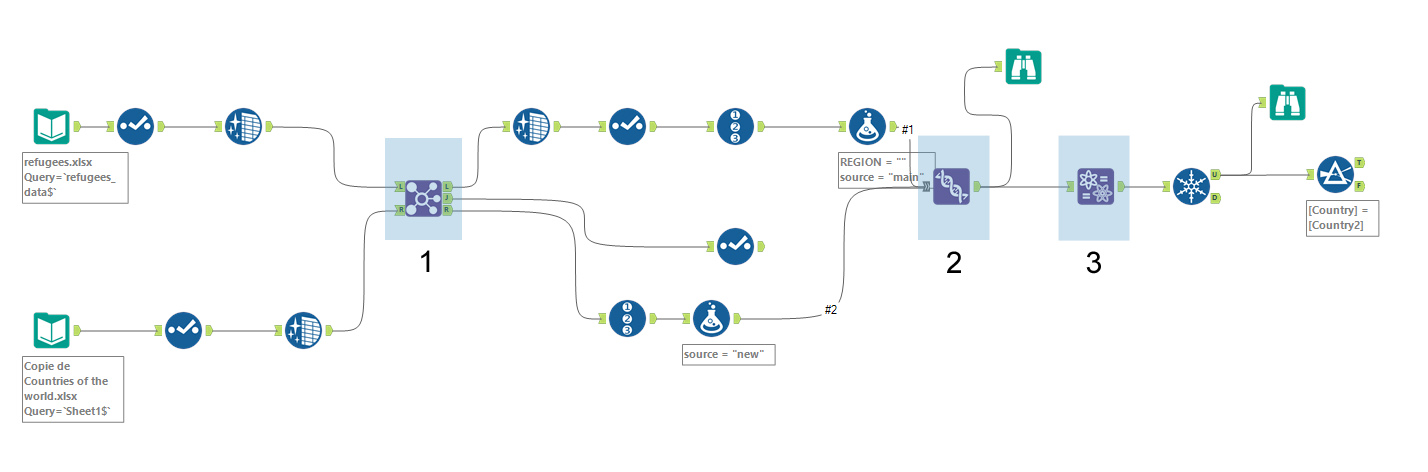
De 3 stappen van fuzzy matching in Alteryx
Voor deze stap koos ik voor dezelfde case als in mijn vorige artikel. Tabel 1 (hierboven) bevat de immigratiegegevens van mensen van buiten de EU naar de Europese Unie. Tabel 2 (hieronder) bevat informatie over ongeveer 200 landen in de wereld. Het land is ingedeeld in een grote regio (Azië, Midden-Oosten, …) en het is die informatie die ik zal proberen toe te voegen. Het probleem is dat de landen tussen de twee tabellen niet allemaal dezelfde schrijfwijze volgen. Vandaar het belang van fuzzy matching.
Stap 1
De eerste stap bestaat erin een koppeling te maken tussen beide tabellen. In J komen alle vermeldingen die overeenkomen met het regioveld dat is toegevoegd. Ik houd deze tabel voor later.
In L komen de gegevens waarvoor geen match werd gevonden. In deze tabel zal ik onder stap twee gaan werken.
Stap 2
In de 2e stap maak ik de koppeling tussen de tabel zonder overeenkomst (L) en de referentietabel (R). Eerst verwijder ik alle overbodige kolommen want de koppeling kan enkel met identieke tabellen.
Stap 3
De derde stap is de eigenlijke fuzzy matching. De fuzzy matching wordt uitgevoerd via de functie “Name” (Engels) onder Alteryx. Het algoritme erachter is van het type dubbele metafoon (meer info daarover hier [Engels]). Het gaat hier, net zoals bij Tableau Prep Builder, over een algoritme dat gebaseerd is op fonetische gelijkenissen.

Resultaten: Alteryx vs. Anatella
Aan het einde van het proces heb ik de lijst met vermeldingen waarvoor een match was gevonden, geëxtraheerd. Op basis van die lijst (hier te downloaden) kunnen we een vergelijking maken met de resultaten verkregen in Anatella via de Dice-methode.
Met een matching-drempel van 75% onder Alteryx, maakt fuzzy matching het mogelijk om 11 van de 20 vermeldingen met elkaar te koppelen (zie onderstaande tabel). Logischerwijze levert het dubbele metafoon-algoritme een vals-positief op door Congo (Congo Brazzaville) en de Democratische Republiek Congo met elkaar te verwarren. Dezelfde fout wordt gemaakt met de methode van Dice.
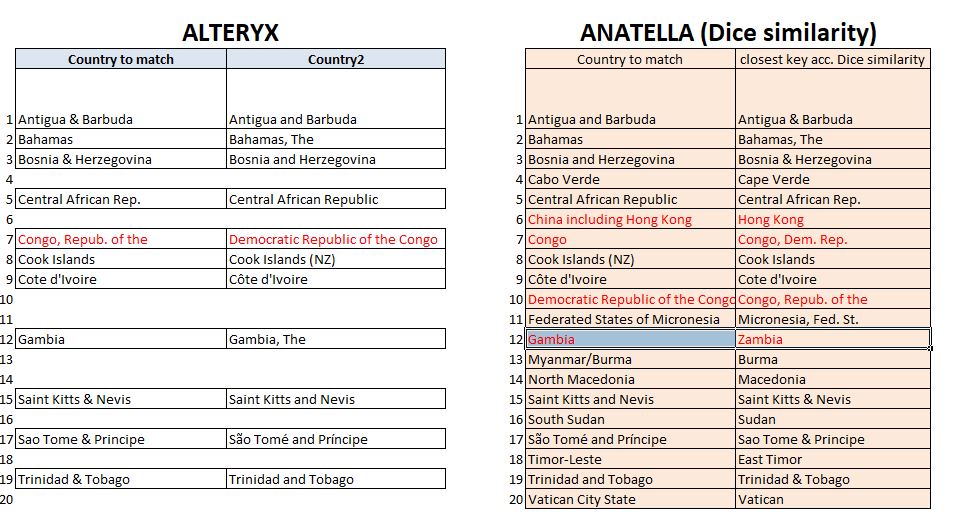
Zonder drempel te specificeren, kregen we onder Anatella 16 op 20 correcte overeenkomsten met de methode van Dice.

Conclusie
Het fuzzy matching-algoritme van Alteryx levert in deze case middelmatige resultaten op. Het algoritme van Dice, beschikbaar in de ETL Anatella, geeft veel betere resultaten.
Bovendien vereist het fuzzy matching-proces in Alteryx onnodige handelingen (koppeling). Het proces onder Anatella verloopt veel eenvoudiger en efficiënter.
Posted in big data.