Wat is de impact van het LinkedIn-algoritme? Wat is de correlatie tussen het aantal likes of commentaren en het aantal views op LinkedIn?
Iedereen probeert inzicht te krijgen in het algoritme van LinkedIn. Sommigen proberen het zelfs te hacken.
Hoewel er theorieën in overvloed zijn, weet niemand echt hoe het werkt. Ik heb mijn mouwen opgestroopt en ga het u vandaag uitleggen, met een statistisch model ter ondersteuning.
BONUS: ontvang uw persoonlijke statistische analyse
Ik stel voor dat u dezelfde analyse uitvoert voor uw LinkedIn-activiteiten. Schrijf u in op onderstaande nieuwsbrief en u krijgt een e-mail met instructies over hoe ik kan helpen. Ik ga wellicht ook een webinar organiseren om u de methode te tonen. Als u op de hoogte wilt blijven, schrijf u dan ook in voor de nieuwsbrief (vergeet niet de bevestigingsmail te valideren die u na het invoeren van uw adres ontvangt).
Als u maar 30 seconden hebt
- Ik heb “manueel” een dataset samengesteld van al mijn publicaties op LinkedIn van de afgelopen 17 maanden.
- Voor elke publicatie werden er metadata gegenereerd (aanwezigheid van een hyperlink, foto’s, …)
- Bij de eerste benadering hield ik geen rekening met andere variabelen (aanwezigheid van een hyperlink bijvoorbeeld)
- De analyse is voor iedereen specifiek en hangt af van de grootte en samenstelling van uw netwerk.
- Een statistische analyse uitgevoerd met Anatella en Tableau toont aan dat elke reactie/opmerking 83 views op LinkedIn oplevert.
- Als u geen likes of commentaren krijgt, blijft uw Linkedin-bericht op ongeveer 300 views hangen.
- Als u wilt weten hoe het algoritme op uw eigen netwerk werkt, stuur me dan een e-mail (of een verzoek op LinkedIn :-), zodat ik u kan helpen.
Samenvatting

Inleiding

Het algoritme van LinkedIn is nog altijd een beetje een mysterie. Een veel voorkomende hypothese is dat het aantal reacties (like, curious, … zie hiernaast) tijdens de eerste 2 uur van de publicatie cruciaal is om de publicatie viraal te maken. Sinds de update van het algoritme kunnen we echter vragen stellen bij deze hypothese.
Het blijft dus een algemene hypothese. Er werd geen onderzoek verricht naar het verspreidingseffect van reacties en commentaren en dus hoeveel mensen er bijkomend worden beïnvloed wanneer iemand reageert of commentaar geeft op uw LinkedIn-post?
Het is precies dat wat ik in het artikel van vandaag zal toelichten.
Focus op Anatella
Anatella is een van mijn favoriete “data”-tools (stuur me een mail voor meer informatie of een demo) en is gratis voor kleine ondernemingen. Het gaat om een ETL-tool (Extract – Tranform – Load) waarmee u grote hoeveelheden data gemakkelijk kunt bewerken voor analyse. Dankzij een uitstekende integratie met R is het bovendien heel eenvoudig om statistische analyses uit te voeren zonder in R te hoeven coderen. Dat komt me goed uit, want hoewel ik heb ik geleerd te programmeren in R doet het gebrek aan praktijk alles snel vervagen.
.
 Methode
Methode
Om de dataset op te bouwen ben ik zo ver mogelijk in mijn berichten teruggegaan voor:
- het aantal views
- de variabelen die het bericht kenmerken (aanwezigheid van hyperlink, foto, video, de tekst van de post, hashtags, …)
Op die manier heb ik 17 maanden geschiedenis verzameld.
De uiteindelijke dataset bestaat uit 257 berichten, verspreid over 17 maanden, gecodeerd volgens 17 variabelen. Uiteindelijk krijgen we een kleine dataset met 4369 punten. Dat is klein, maar de (manuele) inspanning om deze dataset op te bouwen is redelijk aanzienlijk (ongeveer 10 uur werk).
Met het oog op analyse gebruikte Anatella voor datavoorbereiding, Tableau Software voor datavisualisatie en R voor de statistische analyse (via integratie in Anatella).

De gegevensvoorbereiding verloopt via een zeer eenvoudige stroom (zie boven), waarbij ik de gegevens heb opgeschoond, lege velden heb verwijderd en een variabele “comment_reactions” heb gecreëerd die de som vormt van het aantal reacties en het aantal commentaren.
Er werden verschillende soorten eenvoudige modellen getest om het aantal weergaven (afhankelijke variabele) te modelleren. Een polynomiaal model gaf de beste resultaten.

Resultaten
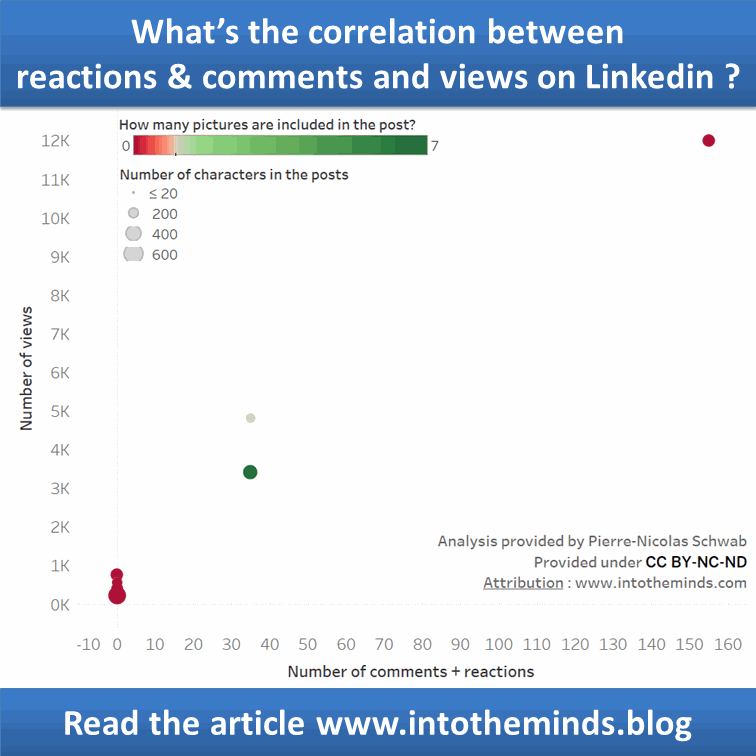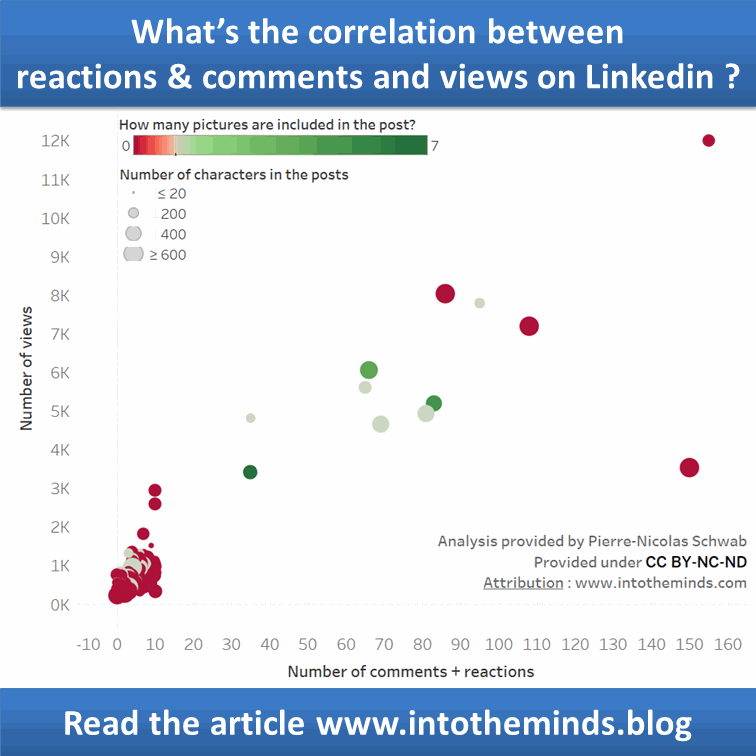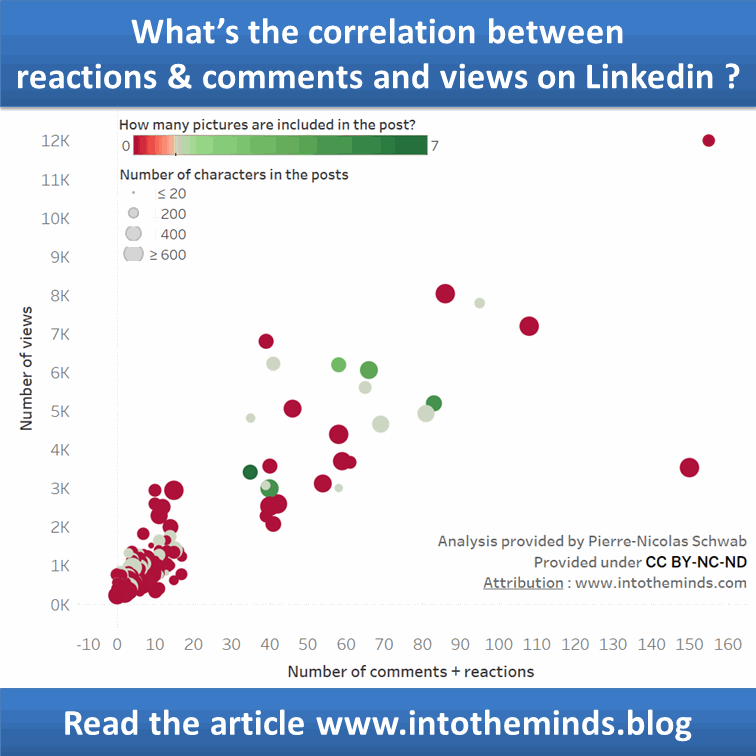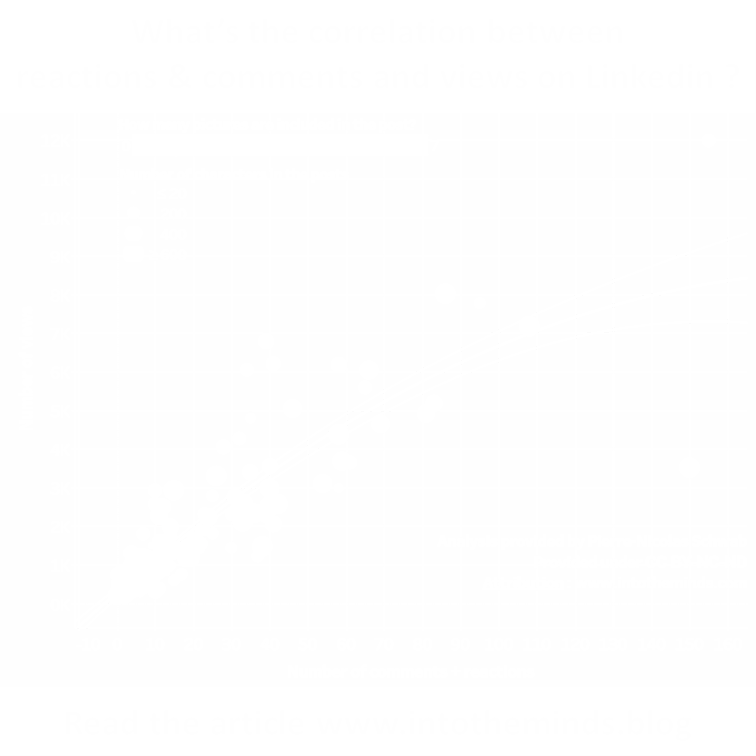
En nu het deel waar jullie allemaal op hebben gewacht. Wat is de relatie tussen het aantal reacties/commentaren en het aantal views?
De grafiek hieronder geeft het resultaat van de modellering weer. U merkt dat een publicatie, zelfs zonder likes en commentaren, toch 303 mensen kan bereiken. Elke like of commentaar levert 83 extra views op. Boven de 100 likes + commentaren toont het model een buiging die vooral te wijten is aan de afwezigheid van meetpunten (slechts 2).

De trendcurve in Tableau geeft ongeveer hetzelfde resultaat (Tableau toont een R² van 0,78; Anatella een pseudo-R² van 0,72).
Ik heb in de visualisering onder Tableau een aantal bijkomende dimensies toegevoegd:
aanwezigheid van foto’s in het bericht: rood als er geen foto is, groen als het aantal foto’s >1 is. De grootte van de meetpunten geeft het aantal karakters van de Linkedin-post weer. Hoe groter de “bubble”, hoe langer het Linkedin-bericht.

Beperkingen
In deze studie hielden we geen rekening met netwerkeffecten. Ook wordt er geen rekening gehouden met de datum en het tijdstip van publicatie, omdat er geen “timestamp” van de publicaties beschikbaar is.
Er zijn weinig meetpunten voor grote view-waarden. Het is daarom noodzakelijk het volume van de dataset te vergroten met zeer populaire (virale) publicaties om het geheel te kunnen remodelleren.
De analyse omvat slechts één persoon (ikzelf), wat natuurlijk de grootste beperking is. Als u wilt bijdragen aan dit onderzoek, neem dan contact met mij op en ik zal de statistische analyse uitvoeren.
Posted in big data.