Na een analyse van mijn meest geschikte publicatietijdstippen op Linkedin heb ik nu een veel moeilijker probleem aangepakt, namelijk het bepalen van de onderwerpen die me de meeste views en reacties opleveren op Linkedin.
In het artikel van vandaag toon ik u de resultaten die behaalde met behulp van 2 specifieke tools, enerzijds Anatella voor de data-extractie en voorbereiding, anderzijds Tableau voor het onderzoeken en visualiseren van de resultaten.
Als u interesse hebt in dit soort analyses en u wenst een onderzoek op maat, neem dan contact met op met mij via e-mail of … via Linkedin 🙂
Als u maar 30 seconden heeft
- Ik ontwikkelde een methode die automatisch de onderwerpen analyseert waar u het meest over hebt gesproken op Linkedin.
- De onderwerpen waar u het vaakst over praat op Linkedin zijn niet noodzakelijkerwijs de onderwerpen die u de meeste likes en commentaar opleveren.
- Het “onderwerp” van een bericht op Linkedin lijkt overeen te komen met het aantal commentaren en likes die u krijgt.
Sommaire
• Inleiding
• Methode
• Evolutie van de onderwerpen op Linkedin per jaar
• Correlatie tussen Linkedin-onderwerpen en aantal views
• Correlatie tussen het onderwerp en het aantal reacties
• Conclusie
• Dankwoord
Inleiding
Welke onderwerpen moet u behandelen op Linkedin om uw netwerk te betrekken? Dat is de onderzoeksvraag die ik mezelf stelde in het kader van mijn onderzoeksprogramma in het laboratorium van LaDisco (Vrije Universiteit Brussel).
Eerst voerde ik een NLP (Natural Language Processing)-analyse uit van elk van mijn +/- 4000 berichten die ik de afgelopen 10 jaar op het sociale netwerk heb geplaatst. Vervolgens koppelde ik de onderwerpen die in elke post aan bod komen aan het aantal views, commentaren en likes die ik ontving.
Dit soort analyses liet me toe een aantal vragen te beantwoorden:
- Hoe zijn uw interesses in de loop der tijd veranderd?
- Wat zijn de onderwerpen die de meeste hits opleveren?
- Welke onderwerpen hebben u de meeste likes en commentaren opgeleverd?
Methode
Om de gegevens van Linkedin te extraheren, heb ik een methode gebruikt die is afgeleid van de methode die ik in een eerder bericht heb uitgelegd. Ik maakte gebruik van twee datasets:
- De geschiedenis van Linkedin over 10 jaar die, dankzij de tijdstempel, een longitudinale analyse van de behandelde onderwerpen mogelijk maakt.
- Een veelheid aan json-bestanden die uit de Linkedin-pagina’s zijn gehaald en die een nauwkeurige reconstructie van het aantal views, commentaren, likes en andere reacties op de laatste 1000 openbare berichten mogelijk maken.
Vervolgens werd de inhoud van elk bericht geanalyseerd via van een NLP-algoritme (Natural Language Processing) dat mij in staat stelde de behandelde thema’s te extraheren. Aan elk bericht worden verschillende thema’s toegekend en er wordt een coëfficiënt toegekend om de betrouwbaarheid van het algoritme inzake de identificatie van het onderwerp weer te geven. Na een snelle controle besloot ik alleen die onderwerpen te behouden waarvan de betrouwbaarheidscoëfficiënt hoger was dan 0,75. Dit elimineert het merendeel van de vals positieven. Ik had nog strikter kunnen zijn, maar dan zouder er minder correlaties te analyseren zijn en zou ik vooral echte echte positieven hebben geëlimineerd.
Opmerking bij de methode: na een gesprek met Bruno Fridlansky, een Franse expert van het Linkedin-netwerk, vroeg deze laatste mij waarom ik geen gebruik maakte van het bestand “reactions.csv” dat in het archiefbestand aanwezig is. De reden daarvoor is dat het bestand “reactions.csv” zeer onvolledig is. De methode die ontwikkeld werd op basis van de extractie van json-bestanden maakt het mogelijk om ongeveer 5000 reacties te traceren over 3 jaar, terwijl het door Linkedin aangeleverde bestand er slechts 1500 telt over een periode van 10 jaar.
Laten we nu overgaan naar de resultaten.
Waarover heb ik de laatste jaren gesproken op Linkedin?
Waarover heb ik de laatste jaren gesproken op Linkedin?
Onderstaande grafiek toont u jaar na jaar de thema’s die ik op mijn Linkedin-profiel heb behandeld (klik op de afbeelding om te vergroten).
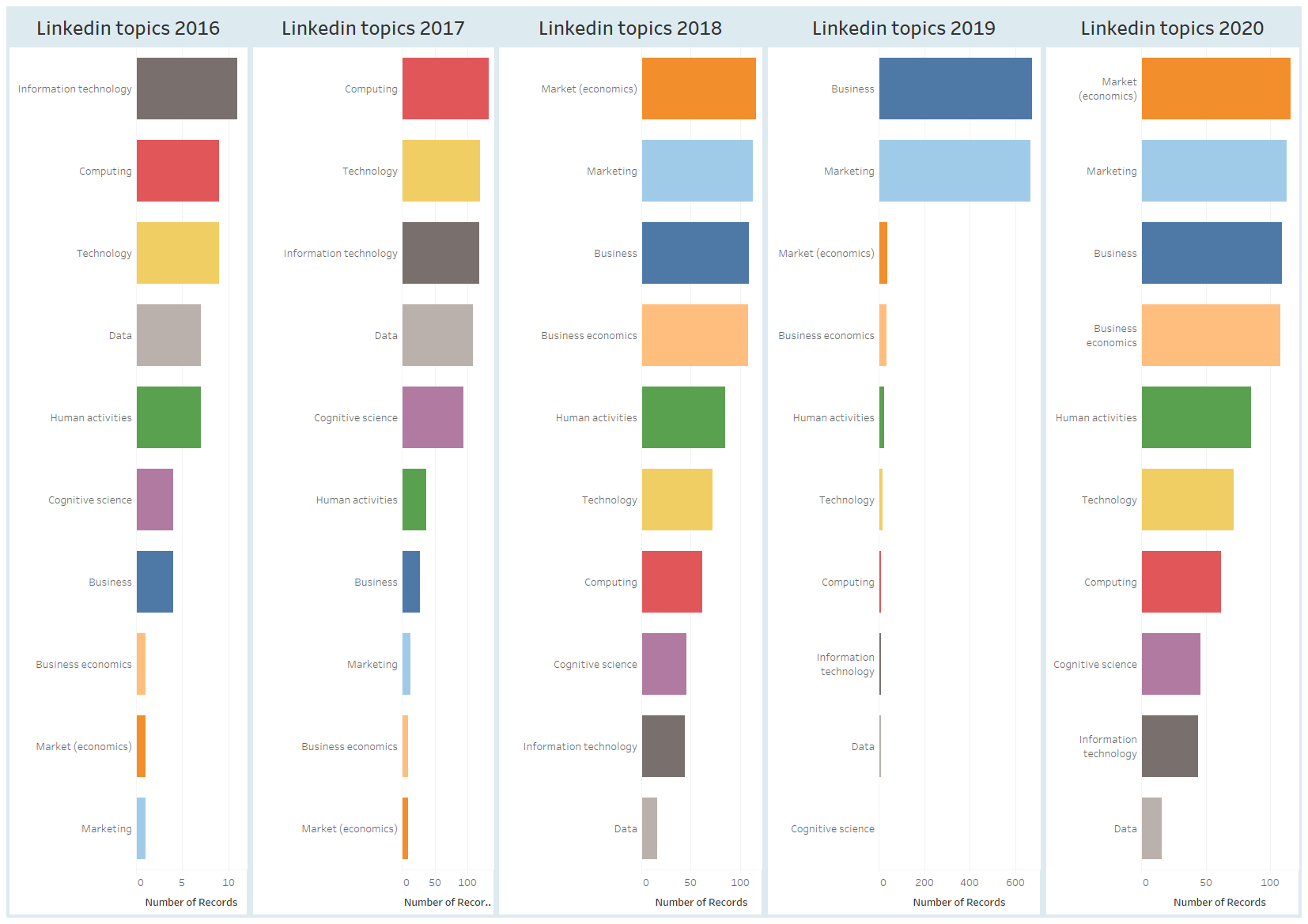
Zoals u merkt, zijn mijn favoriete onderwerpen niet hetzelfde gebleven en weerspiegelen ze eerder de projecten waaraan ik werkte en de interesses die ik ontwikkelde.
Ik was verbaasd te zien dat mijn publicaties in 2019 werden gedomineerd door 2 onderwerpen (business en marketing) en dat de technologische aspecten die in voorgaande jaren de boventoon voerden, dat jaar naar de achtergrond verdwenen. De balans lijkt in 2020 weer in evenwicht te zijn.
In plaats van over alles en nog wat te praten op Linkedin, waarom zou u zich niet richten op datgene wat u het meest aanspreekt?
Wat zijn de onderwerpen die mij de meeste views hebben opgeleverd op Linkedin?
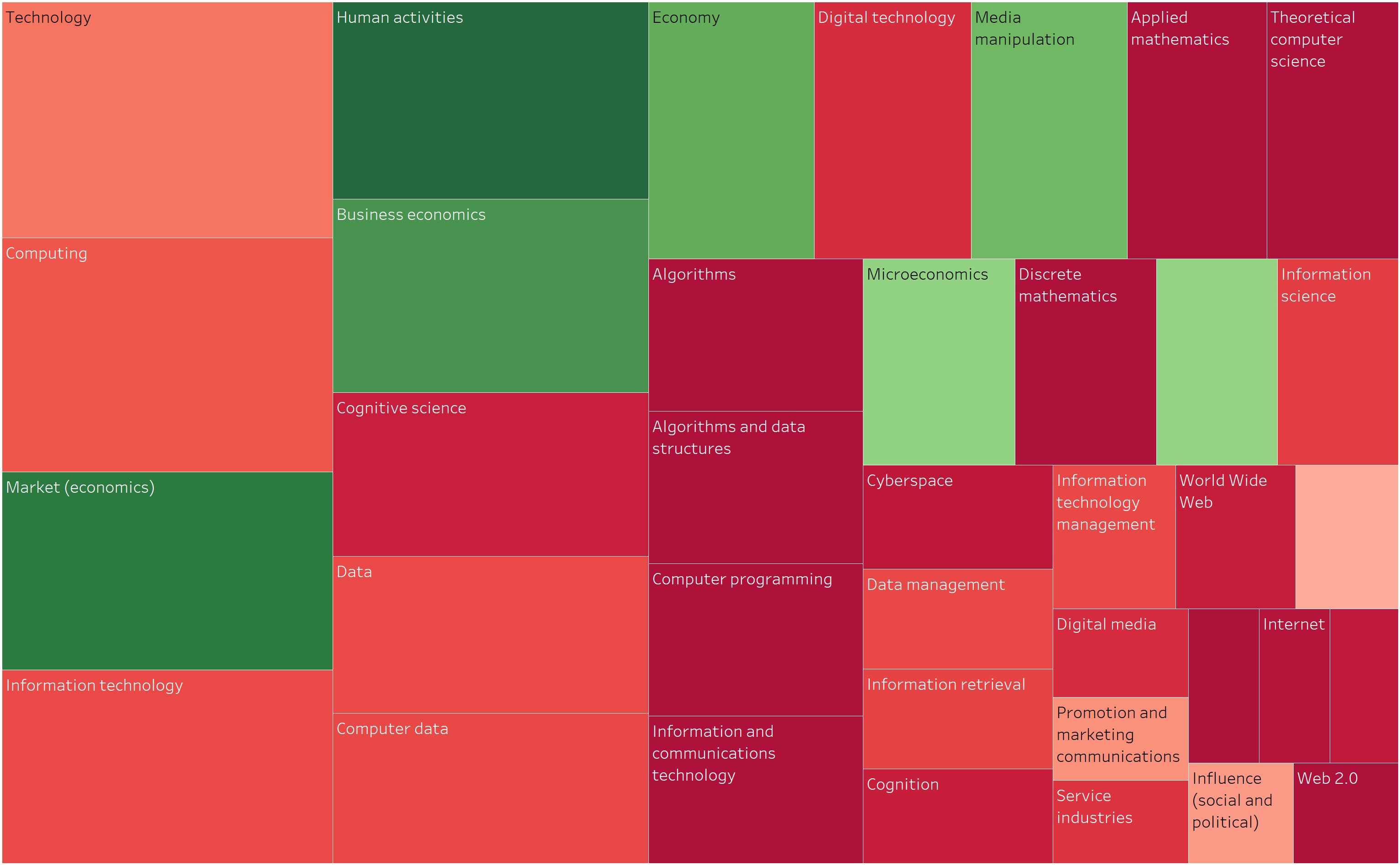
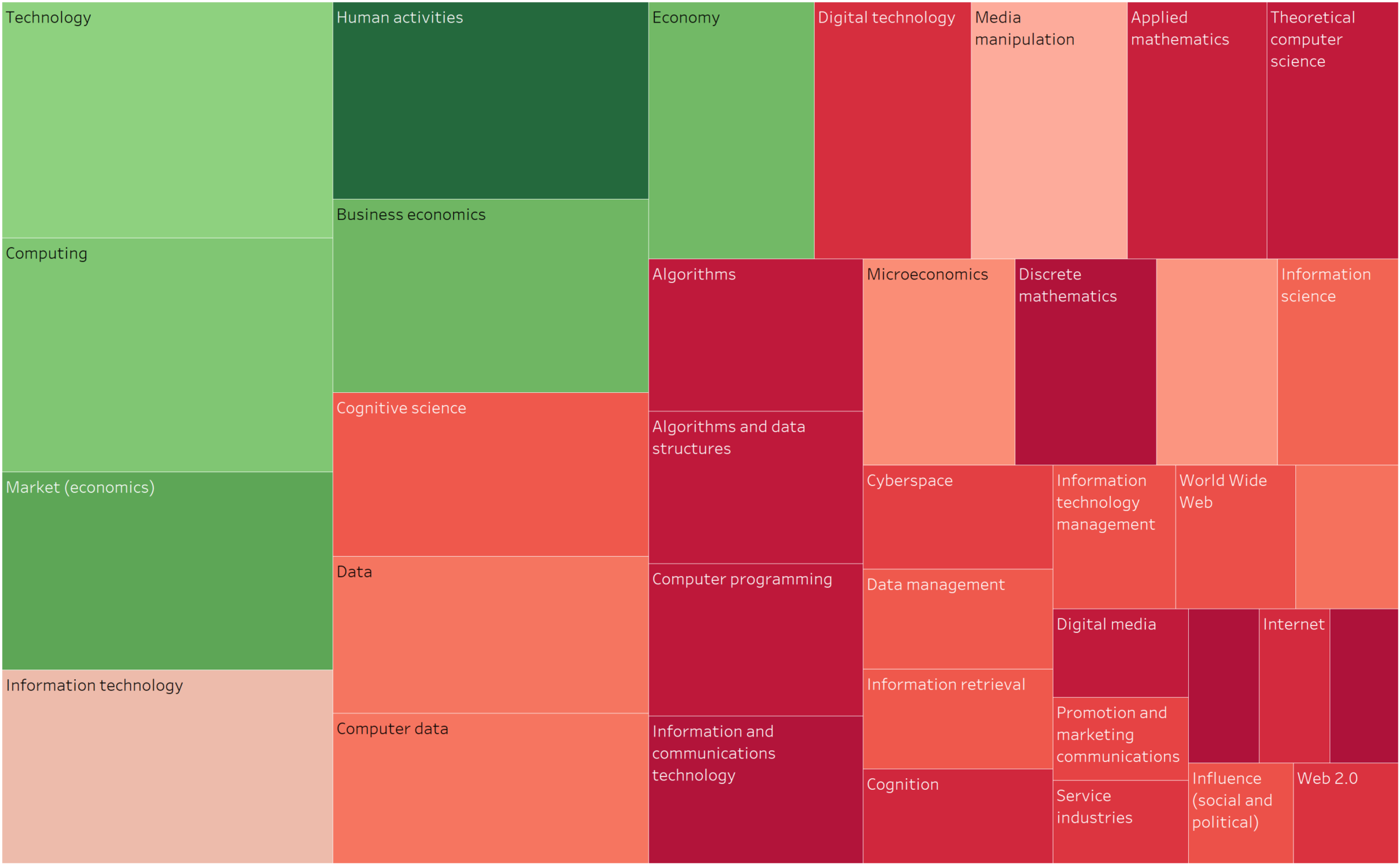
Dit is een vraag die iedereen zich moet stellen. Niet alle onderwerpen zijn noodzakelijkerwijs geschikt voor Linkedin. Uw netwerk kan gevoelig zijn voor bepaalde onderwerpen en die moet u kennen. In plaats van over alles en nog wat te praten op Linkedin, waarom zou u zich niet richten op wat u het meest aanspreekt? Dat is precies wat ik heb geprobeerd te achterhalen door de onderwerpen die in de loop der jaren aan bod zijn gekomen weer te geven in de vorm van een “treemap” aan de ene kant, en vervolgens een kleurindicator toe te voegen om de onderwerpen die het meest opleveren te identificeren.
Welke onderwerpen hebben de meeste betrokkenheid op Linkedin opgeleverd?
De laatste vraag, tot slot, is de betrokkenheid van uw netwerk. Ook dit is een thema dat vaak bij Linkedin-experts aan bod komt: “u moet over dit of dat praten om reacties van uw netwerk te krijgen”.
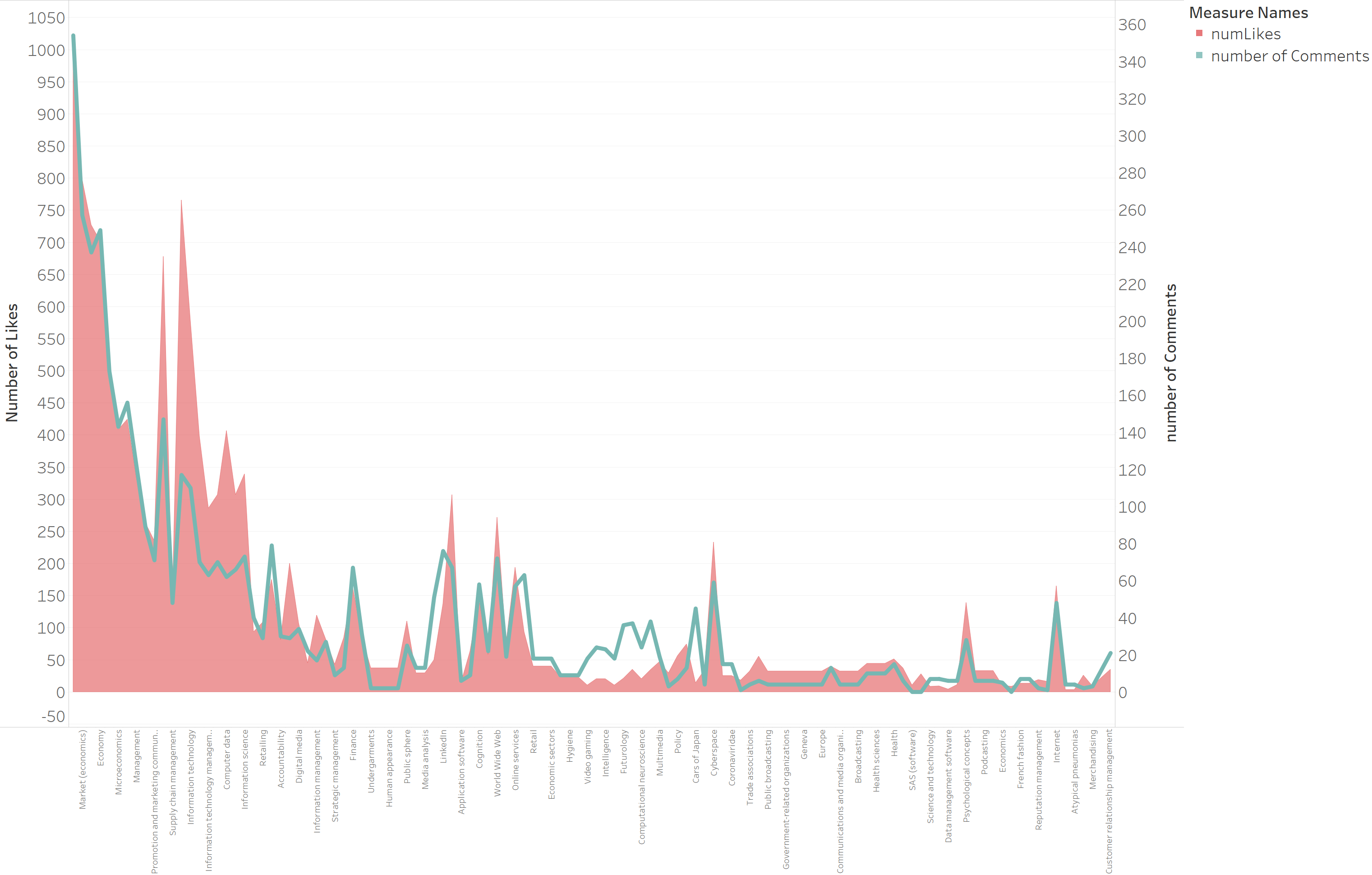
Om tot de kern van de zaak te komen, wilde ik er het fijne van weten. Ik heb enerzijds de behandelde onderwerpen weergegeven in de vorm van een histogram, en anderzijds het aantal commentaren en likes die ze opleverden.
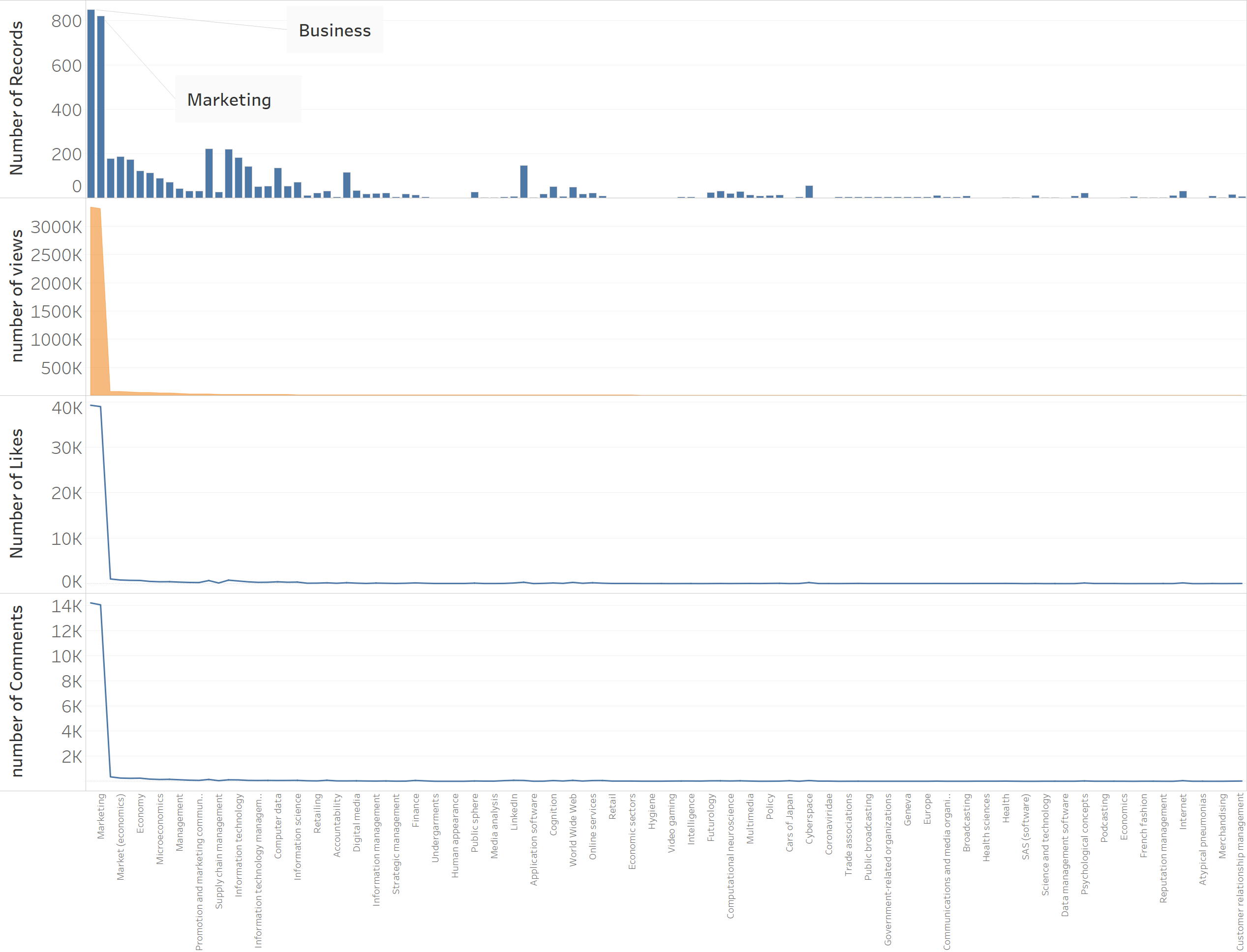 Zoals u merkt, zijn de thema’s “business” en “marketing” de thema’s die de meeste reacties opleveren. Om een duidelijker beeld te krijgen, heb ik deze onderwerpen daarom tijdelijk uit de analyse gehaald om te voorkomen dat ze de anderen “overweldigen”.
Zoals u merkt, zijn de thema’s “business” en “marketing” de thema’s die de meeste reacties opleveren. Om een duidelijker beeld te krijgen, heb ik deze onderwerpen daarom tijdelijk uit de analyse gehaald om te voorkomen dat ze de anderen “overweldigen”.

U merkt vooreerst dat de curve van “likes” en “comments” elkaar vrij goed volgen als u deze analyseert in termen van het onderwerp (zie bovenstaande grafiek). Er bestaat dus duidelijk een correlatie tussen het aantal likes en het aantal reaties op een Linkedin-bericht.
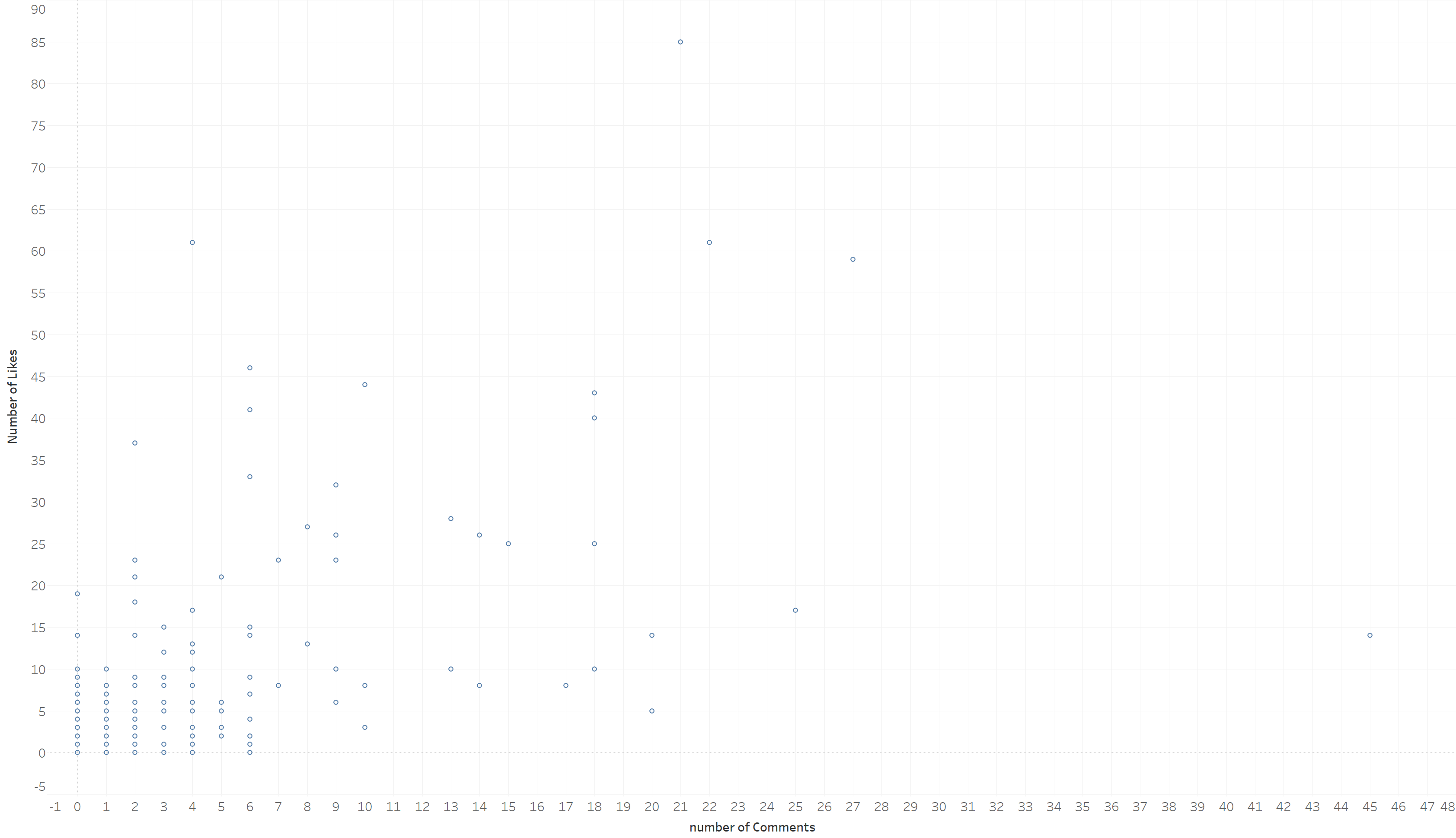
Aan de andere kant is deze correlatie niet zo duidelijk met een traditionele scatter plot (zie hierboven). We kunnen dus vermoeden dat de variabele “onderwerp van het Linkedin-bericht” een matigende variabele is.
Om de resultaten nog duidelijker te maken, heb ik de “treemap” opnieuw gebruikt en een kleur toegevoegd om het aantal ontvangen reacties (likes + commentaren) aan te geven. Zoals u ziet, zijn de onderwerpen die ik het vaakst behandelde niet noodzakelijkerwijs de onderwerpen die de meeste betrokkenheid hebben opgeleverd.
Conclusies
Dit vooronderzoek maakt het mogelijk een methodologie te valideren om 1) thema’s te extraheren uit openbare berichten die op Linkedin worden geplaatst, en 2) deze thema’s te koppelen aan het aantal views, commentaren en likes.
De gegevens die op die wijze worden geëxtraheerd, maken het mogelijk om enerzijds de evolutie van iemands interesses in tijd te visualiseren en anderzijds de onderwerpen die het meest opleveren te bepalen.
Dit werk is slechts een eerste stap naar een meer globale aanpak om de dynamiek van het Linkedin-netwerk te begrijpen. Sturende variabelen zoals de grootte van het netwerk en het tijdstip van publicatie worden hier niet in aanmerking genomen.
Dankwoord
Aan het einde van deze eerste mijlpaal van mijn onderzoek wil ik graag Frank Vanden Berghen, Raphaël Vander Marcken en Michael Silvestre bedanken voor hun waardevolle bijdrage bij de totstandkoming van deze analyse.
Dank ook aan Frank en Raphaël voor hun aanpassingen aan Anatella voor dit onderzoek.
Posted in Data en IT.