ChatGPT tiene una habilidad sorprende: si haces clic en el botón de «regenerar respuesta», ChatGPT propondrá una respuesta completamente nueva. Al menos a nivel superficial porque, en realidad, los resultados publicados en este artículo muestran que ChatGPT se repite mucho. ¡Tanto, que incluso las respuestas a preguntas distintas tienen el mismo aspecto! Esto confirma la primera investigación que publicamos sobre este tema. Hoy mostraremos todavía más que cuanto menos precisa sea tu pregunta a ChatGPT, más parecidas serán las respuestas. La tasa de parecido alcance de media el 77,91%.
Los datos para este proyecto han sido preparados y enriquecidos con la solución ETL de Timi: Anatella. La visualización de los datos se ha realizado con Tableau.
Qué puede aprender de esta investigación sobre el funcionamiento de ChatGPT
- 505,1 palabras: la longitud media de los 1.000 textos producidos por ChatGPT basados en una longitud solicitada de 500 palabras.
- 1%: el respeto de ChatGPT hacia los datos ofrecidos en términos de longitud del texto.
- Los textos producidos por ChatGPT con instrucciones mínimas son significativamente más parecidos (77,91%) que cuando se dan instrucciones detalladas (73,17%).
- Cuando las instrucciones dadas a ChatGPT son menos detalladas, las respuestas a distintas preguntas son mucho más parecidas (65,44%) que cuando se dan instrucciones detalladas (60,93%)
- Sin importar la pregunta, ChatGPT muestra una capacidad asombrosa de producir respuestas parecidas cuando le pides que reformule su respuesta (un parecido con una media de entre 76,02 y 80,04%, según la pregunta). Así que espera recibir respuestas solo parcialmente diferentes de una reformulación a la siguiente.
Metodología
Le hice a ChatGPT 20 preguntas. Para cada pregunta, le pedí que la reformulase 50 veces, correspondiéndose con 50 iteraciones. Así que analicé 1.000 respuestas.
Aquí tienes un ejemplo.

Para regenerar una respuesta, se le da clic al botón que hay a continuación:
Las preguntas eran todas idénticas en la forma:
Escribe un artículo optimizado para SEO de 500 palabras sobre «PALABRA CLAVE»
Solo la «palabra clave» difería entre una serie y otra. La lista de palabras clave está disponible al final de este artículo.
Al final, 20 preguntas x 50 iteraciones = se analizaron 1.000 textos
Una vez extraídos los datos de ChatGPT, estos se prepararon con el software ETL. Para la preparación de los datos, utilicé exclusivamente Anatella, lo mejor en su categoría (aquí puedes ver mi consejo a la hora de elegir un ETL). La visualización de los datos se realizó con Tableau.
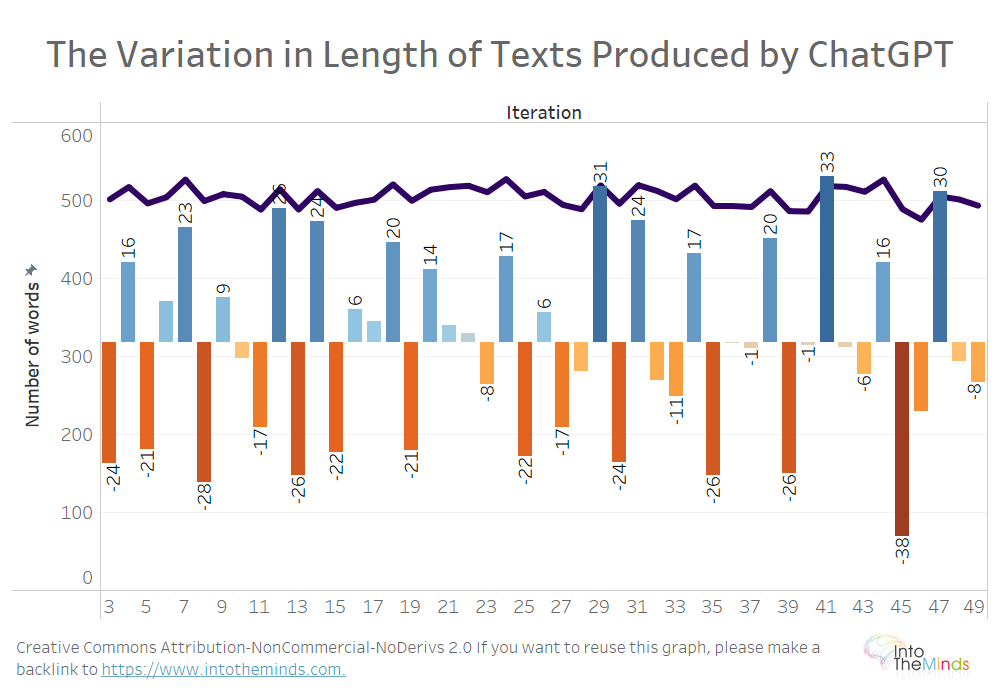
ChatGPT respecta las instrucciones sobre la longitud del texto
La primera lección de esta investigación es que ChatGPT respecta las instrucciones en cuanto a conteo de palabras relativamente bien. De los 1.000 textos producidos, el número medio de palabras por texto fue de 505,1. Es un rendimiento increíble, ya que significa que los datos aportados a ChatGPT fueron respetados con una tolerancia de a duras penas el 1%. Los creadores de contenido quedarán encantados, ya que encontrarán una manera ultra simple de producir contenido genérico para sus páginas web.
Eso es lo que se puede ver en el gráfico inferior con la línea púrpura. Las barras indican la desviación media de una iteración a la siguiente. Por ejemplo, hubo 24 palabras menos entre la primera y la segunda iteración.
En nuestro experimento previo, no le dimos a ChatGPT ninguna instrucción sobre la longitud del texto, y la media fue de 253,7 palabras con tolerancias de +8,3%/-7,6%. Por lo tanto podemos hipotetizar que presentar un objetivo en las instrucciones a ChatGPT nos permite obtener un resultado mucho más acertado.
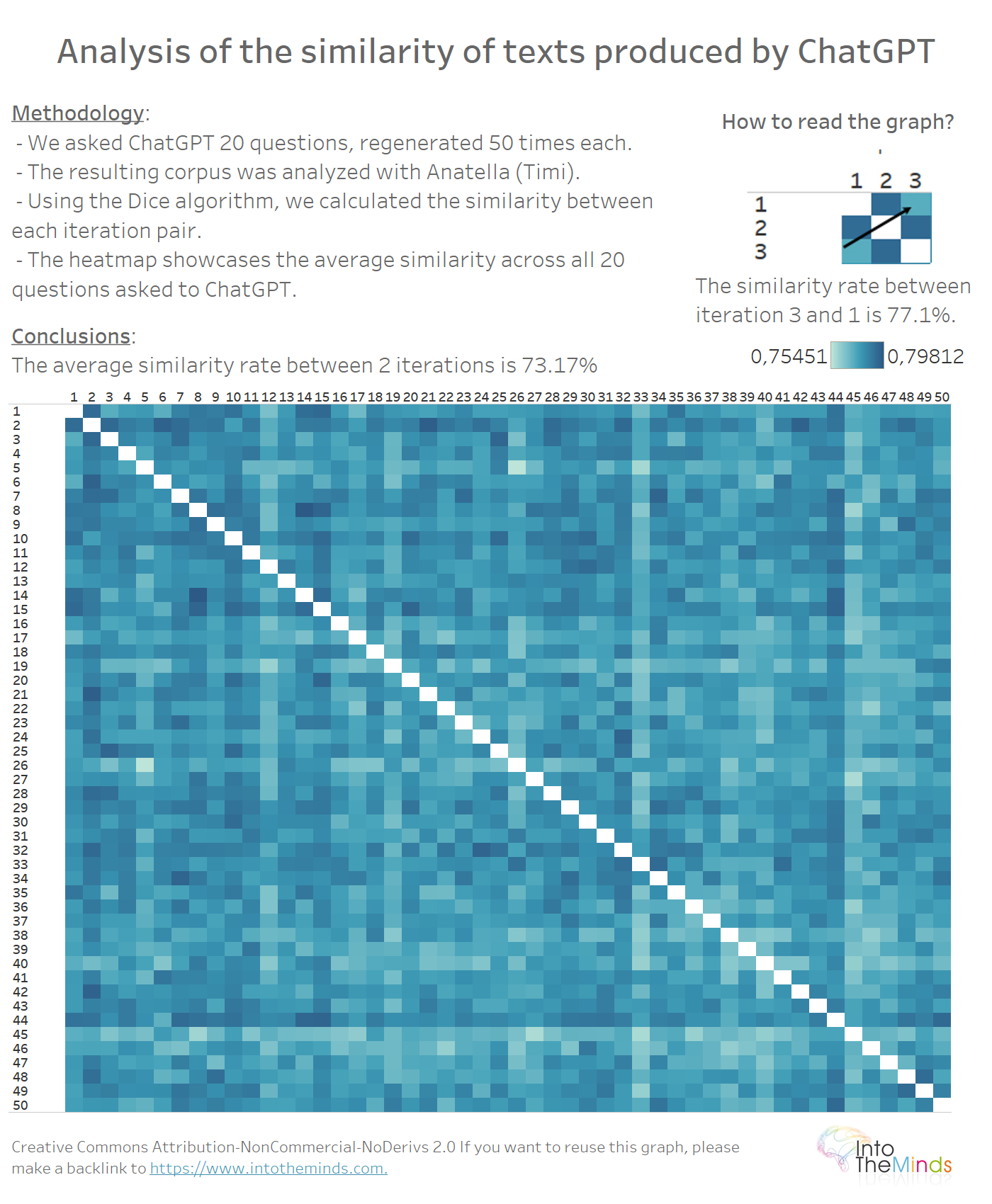
77,9% de parecido: ChatGPT responde a la misma pregunta de manera muy parecida
En nuestra primera investigación, medimos una tasa de parecido del 72%. En ese momento le dimos a ChatGPT instrucciones precisas en cuanto a la estructura del texto a producir. Con instrucciones más vagas, vimos que la tasa media de parecido aumentaba hasta el 77,9%.
El mapa de calor que hay a continuación representa la tasa de parecido entre 2 iteraciones. En otras palabras, cada cuadrado coloreado se usa para valorar lo parecidos que son los resultados producidos por ChatGPT entre 2 iteraciones. La tasa de parecido se computó gracias a Anatella (mi ETL preferida 😀) utilizando el método Sorensen-Dice. Hay muchos otros métodos, pero este ofrece excelentes resultados (aquí puedes ver el benchmark de 4 algoritmos de emparejamiento difuso disponibles de manera nativa en Anatella).
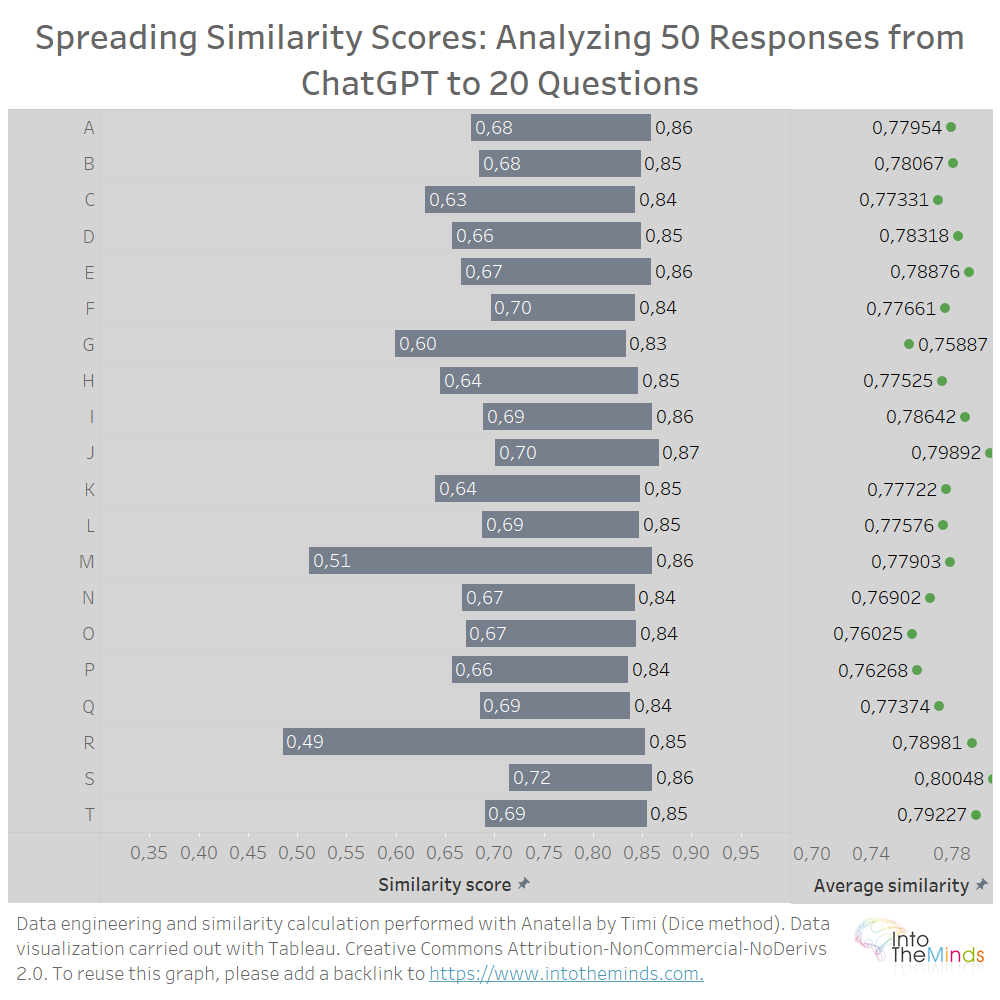
Por supuesto, también es posible representar los resultados de cada una de las 20 preguntas realizadas. Es lo que se hizo a continuación. Verás que las medias de cada conjunto son muy cercanas entre sí, lo que significa que cuando le pides a ChatGPT que reformule sus textos, los resultados serán, de media, muy parecidos a los anteriores, sea cual sea la pregunta. Esto no evita que haya algunos accidentes (las series M y R, por ejemplo). En estos 2 casos, un análisis más detallado muestra que ChatGPT produjo 2 textos de longitudes muy diferentes (200 palabras de diferencia) entre 2 iteraciones sucesivas. La tasa de parecido se ve afectada por ello por necesidad.
¿Qué podemos aprender de estos gráficos? Que ChatGPT es sorprendentemente estable cuando le pides que reformule una respuesta. Incluso si el texto propuesto parece distinto, al final no es más que las mismas palabras presentadas en un orden distinto. Lo estoy exagerando un poco, pero ese es el espíritu de los resultados.
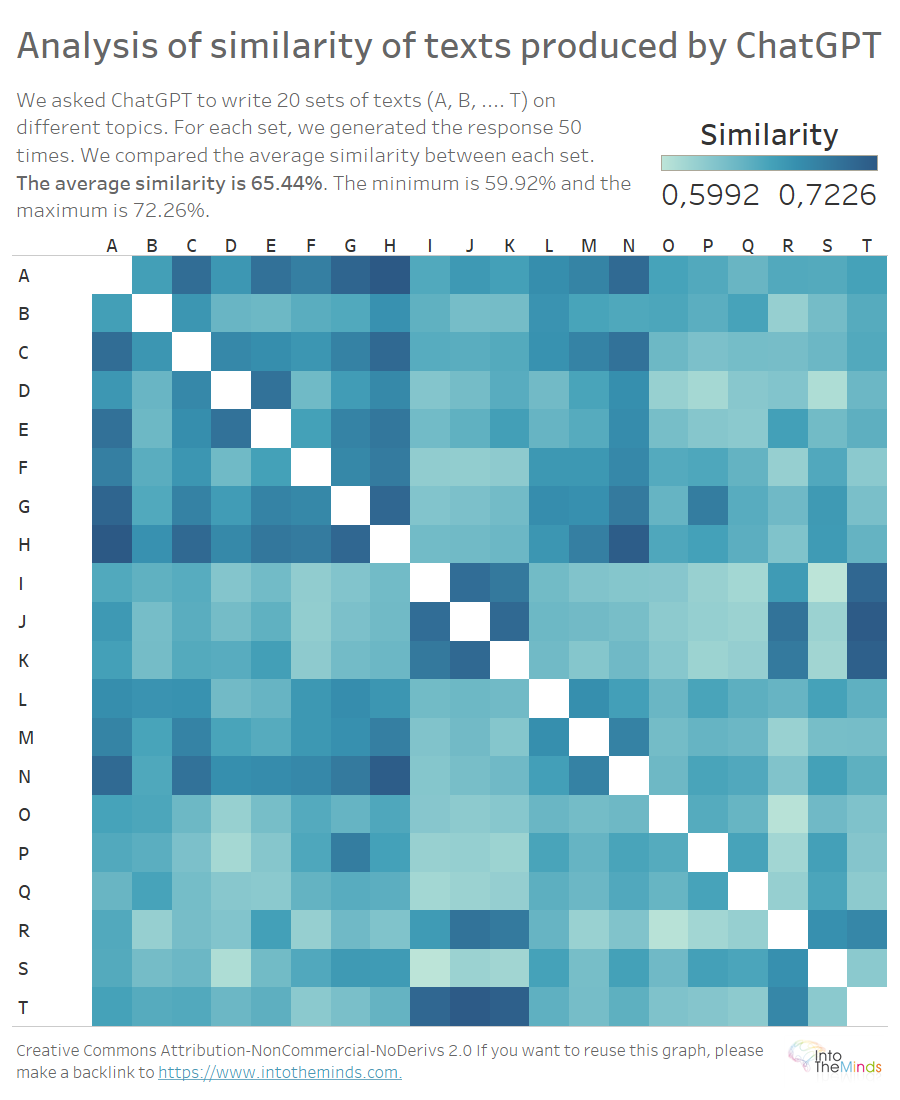
65,44% de parecido entre respuestas a distintas preguntas
El último análisis que realizamos fue para investigar el parecido de las respuestas a preguntas distintas. En otras palabras, calculamos el parecido medio entre todas las respuestas a la pregunta A y todas las respuestas a la pregunta B. Y repetimos este análisis cruzado para cada pregunta.
El ejercicio era simple, pero presentaba algunos retos técnicos debido a las limitaciones del software de visualización (Tableau). Anatella me permitió esquivar ese problema preparando los datos fuera de Tableau (y con muchas rapidez, como ya mostré aquí). El resultado vuelve a presentarse en un mapa de calor (a continuación).
Los resultados hablan por sí mismos: el parecido medio entre preguntas es del 65,44%. En otras palabras, las respuestas de ChatGPT a preguntas diferentes son parecidas en 2/3. Por supuesto, la presentación de las distintas preguntas fue la misma, pero este resultado sigue siendo intrigante. Las preguntas presentadas fueron relativamente tersas, sin más instrucciones que el conteo de palabras. Aunque los temas son diferentes, las respuestas ofrecidas por ChatGPT parten del mismo molde.
Estoy debería animarte a ser muy detallado en tus solicitudes a ChatGPT. Cuanto más concreto seas, más probable es que recibas respuestas únicas y no repetitivas.
Proceso de transformación de datos
Toda la preparación de datos se realizó con Anatella, que es una solución software ETL (Extract – Transform – Load). Con un ETL, puedes extraer datos, transformarlos (correcciones, enriquecimiento, etc.) y reinyectarlos en otro software.
Las razones que me llevaron a elegir Anatella para este proyecto son 3:
- Velocidad (ver un benchmark aquí):
- Herramientas disponibles para el cálculo de parecido
- Reactividad del editor (Timi), que me propuso un desarrollo personalizado para dar respuesta a una necesidad que no estaba cubierta
Se crearon tres flujos de preparación de datos distintos bajo Anatella. Cada flujo me permitió avanzar más el análisis y explorar las respuestas de ChatGPT de manera distinta.
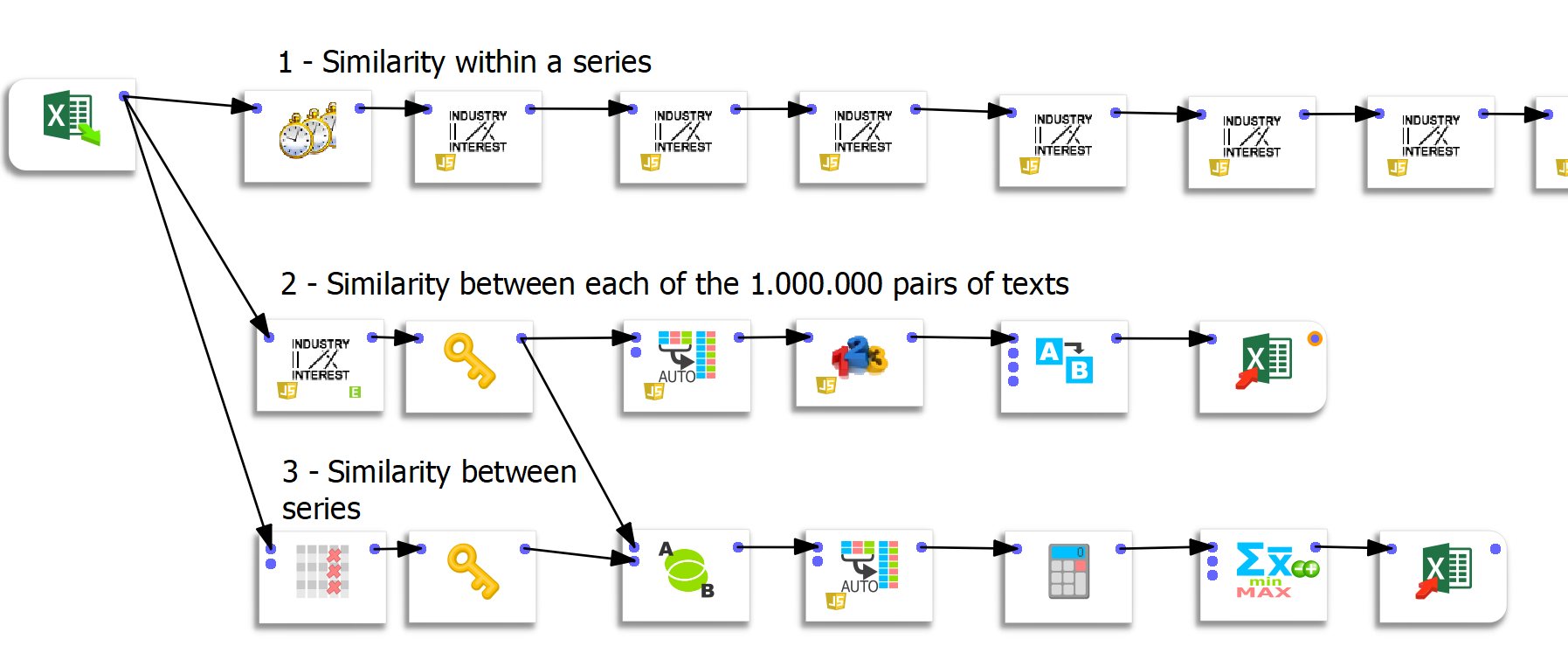
Flujo 1: Computar parecidos dentro de una serie
En este primer flujo, computé los parecidos entre cada iteración de manera secuencial. Anatella tiene una característica lista para su uso para ello, algo muy conveniente. Solo tienes que montar las cajas para obtener el resultado deseado.
Flujo 2: Calcular el parecido entre cada pareja de textos
Para llevar a cabo esta operación, Timi me ofreció una característica personalizada. Se trata de una «caja» que permite calcular el parecido entre cada texto a la vez. Por lo tanto, esta caja hace posible calcular con facilidad 1.000.000 de parecidos (1.000 columnas x 1.000 líneas) de una sola vez.
Un punto técnico extremadamente importante gira en torno a la ingestión de datos en Tableau. Tableau solo puede manejar 700 columnas, lo que hace imposible rotar estos datos en Tableau de manera directa. Así pues, el uso de Anatella fue una ayuda muy apreciada y vital para el éxito del proyecto.
Flujo 3: Cálculo del parecido entre series
El último flujo nos permitió calcular el parecido entre las respuestas a las diferentes preguntas.
Lista de temas
Aquí tienes la lista de temas que hemos presentado a ChatGPT.
| Referencia | Tema |
| A | Marketing de activación |
| B | Astroturfing |
| C | Gender marketing |
| D | Marketing como servicio |
| E | Automatización de marketing |
| F | Marketing emoticonos |
| G | Marketing reactivo |
| H | Street marketing |
| I | Net Promoter Score |
| J | Experiencia del cliente |
| K | Customer Lifetime Value |
| L | Seguridad de marca |
| M | Marketing de famosos |
| N | Buzz marketing |
| O | Llamada a la acción |
| P | Secuestro de noticias |
| Q | Microblogging |
| R | CRM social |
| S | Planificación redes sociales |
| T | Tasa de rotación |
Posted in Investigación.