Potentieel kan het een enorm schandaal worden. Kate Crawford plaatste op Twitter (zie screenshot hieronder) een reactie van Bard, de chatbot van Google die gebruik maakt van generatieve AI, op de onschuldige vraag: “Waar komen de gegevens van Bard vandaan?
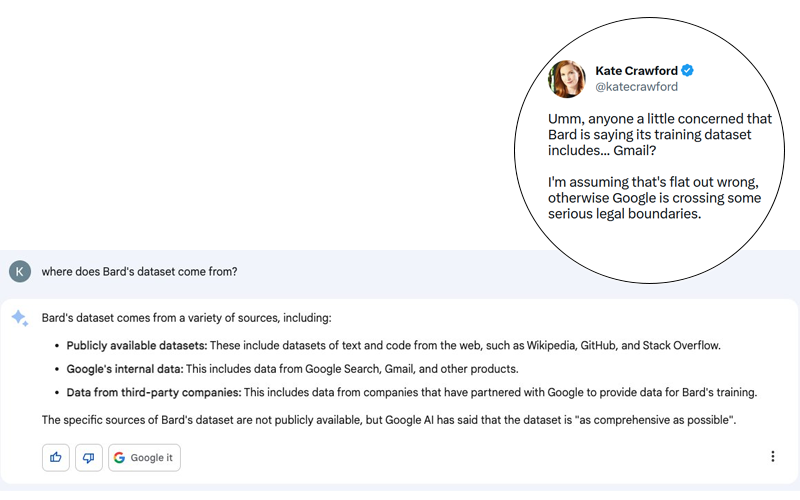
Hoewel het bij de reactie van Bard om een hallucinatie kan gaan, denk ik dat het belangrijk is eraan te herinneren dat Google al bewezen heeft zelfs de meest elementaire privacy- en gegevensbeschermingsregels te negeren. Het zou me dan ook niet verbazen als er een kern van waarheid in dit verhaal zit, ook al werd het relatief snel door Google ontkend (zie onderstaande tweet).
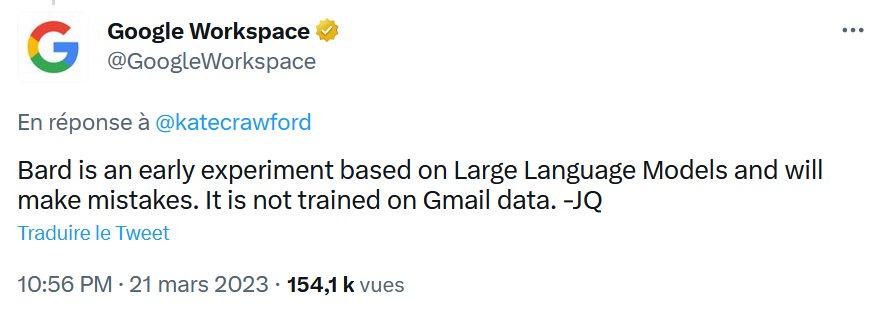
Laten we inderdaad niet vergeten dat Google tot 2017 (Engelse site) de e-mails van zijn gebruikers scande om contextuele advertenties aan te bieden. Google stopte met deze zeer opdringerige praktijk om zijn betalende klanten niet af te schrikken … en ook vanwege rechtszaken, vooral de zaak Matera vs. Google (Engelse site). Toch is Google niet gestopt met (Engelse site) het analyseren van uw e-mails. In Gmail zitten nog altijd functies die gebruik maken van ongestructureerde gegevens in e-mails die via Gmail worden ontvangen:
- evenementen toevoegen aan uw agenda
- voorspellend typen
- voorgestelde herinneringen
Wat zeker is, is dat de hallucinatie van Bard ons zou moeten waarschuwen voor de mogelijke gevaren van dergelijke technologische vooruitgang. Wat mij zorgen baart is niet zozeer de vooruitgang zelf, maar veeleer de mensen achter die vooruitgang en hun keuzes. In het geval van generatieve AI en de LLM’s die daaraan ten grondslag liggen, zijn het de trainingsgegevens die mij de meeste zorgen baren. Vooral omdat de uitleg van OpenAI bij de release van GPT-4 allesbehalve transparant is over de gegevens die zijn gebruikt om dit nieuwe model te trainen.

Risico’s verbonden aan het gebruik van chatbots
De risico’s houden vooral verband met inbreuken op de wetgeving inzake de vertrouwelijkheid van correspondentie. Dit stond al centraal in de zaak Matera vs. Google. De schikkingsovereenkomst tussen de partijen werd door de rechters verworpen omdat de door Google voorgestelde maatregelen onvoldoende waren om ervoor te zorgen dat de oorzaken van het probleem zouden worden verholpen.
Deze inbreuk op het briefgeheim vormt een nog groter risico voor bedrijven: de eerbiediging van het bedrijfsgeheim. Kunt u zich even voorstellen dat uw vertrouwelijke gesprekken (en mogelijk beschermd door een NDA) kunnen worden gebruikt als trainingscorpus voor een kunstmatige intelligentie? Iets verderop in dit artikel geef ik een vrij bekend voorbeeld.
Stelt u zich dit scenario eens voor. Een investeringsbank werkt aan een project om bedrijf A van bedrijf B te kopen. De beurzen dienen als oefenterrein voor Bard. 10.000 km verderop vraagt een analist aan Bard om een overzicht van de situatie met betrekking tot bedrijf A. Bard antwoordt dat A zou kunnen worden overgenomen door B. Is dit een scenario? Bard antwoordt dat A zou kunnen worden overgenomen door B. Is dit scenario echt zo utopisch?
Wat mij het meest beangstigt in dit verhaal is dat vertrouwelijke gegevens worden geïntegreerd in de antwoorden van een algoritme waarvan de werking de ontwerpers nog steeds ontgaat. Zoals ik hier heb uitgelegd, is de toegevoegde waarde van mijn marktonderzoeksbureau gebaseerd op het genereren van zogenaamde “primaire” gegevens. Dit zijn gegevens die ad hoc worden verzameld voor de behoeften van een klant en waarvoor klanten betalen. Het zou onbegrijpelijk zijn als deze gegevens, die wij dagelijks per e-mail uitwisselen, zouden worden gestolen en aan derden zouden kunnen worden doorgegeven.
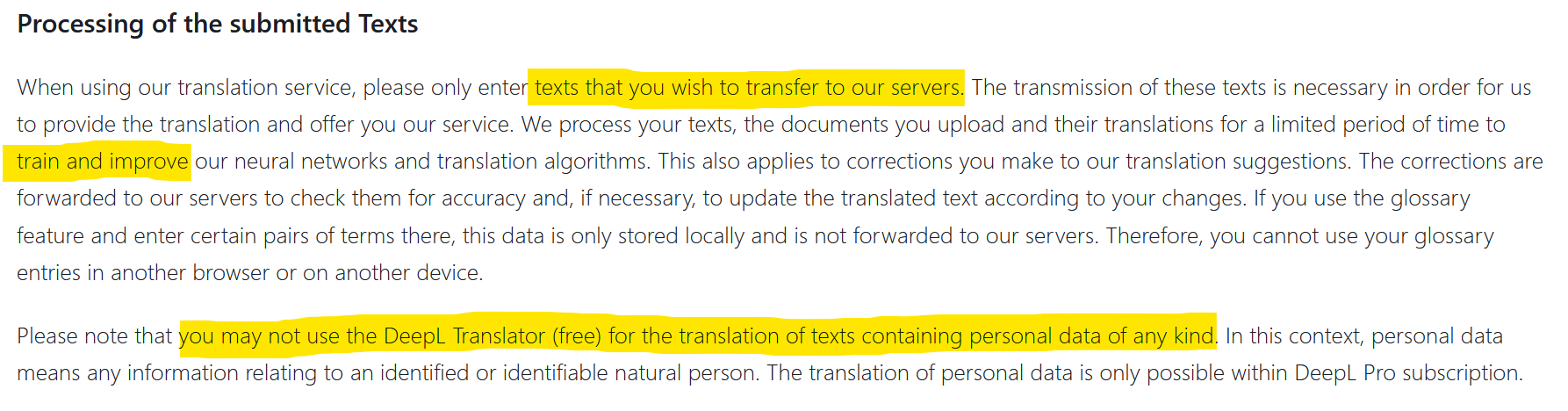
Tot nu toe waren de gegevens van bedrijven die naar de buitenwereld lekten afkomstig van hacking. Maar soms was het ook nalatigheid die gegevens aan de buitenwereld blootstelde. Het gebruik van Deepl is bijvoorbeeld afhankelijk van de toestemming voor de overdracht en verspreiding van de informatie die u doorgeeft (zie screenshot hierboven). Vertrouwelijke gegevens kunnen dan op het internet terechtkomen. Dit is wat Statoil in 2017 (Engelse site) overkwam na het gebruik van translate.com. Uit een onderzoek (Engelse site)van de Noorse media NRK bleek dat privé en zeer vertrouwelijke gegevens in overvloed op deze vertaalsite stonden. Wat zal er gebeuren als duizenden bedrijven ChatGPT plug-ins gebruiken? Wat zal het niveau van privacy zijn? Waar gaan de uitgewisselde gegevens heen en worden ze opgenomen in de trainingsdatasets?

Conclusie
Ter afsluiting wil ik de lezer eraan herinneren dat de eerste gebruikers van nieuwe technologische hulpmiddelen potentieel proefkonijnen zijn. In het geval van ChatGPT vormde het enorme aantal gebruikers tijdens de begindagen een krachtige hefboom voor OpenAI. Maar de ondoorzichtigheid van dit gratis product doet mij geloven dat we de komende maanden wel eens voor verrassingen kunnen komen te staan. Dit is des te realistischer omdat de ontwerpers van ChatGPT niet echt begrijpen hoe hun creatie werkt en (terecht) onder de indruk zijn van de resultaten.
Posted in Data en IT.